| CPC G06F 11/3006 (2013.01) [G06F 8/656 (2018.02); G06F 11/0772 (2013.01); G06F 11/0793 (2013.01)] | 19 Claims |
|
1. A method, comprising:
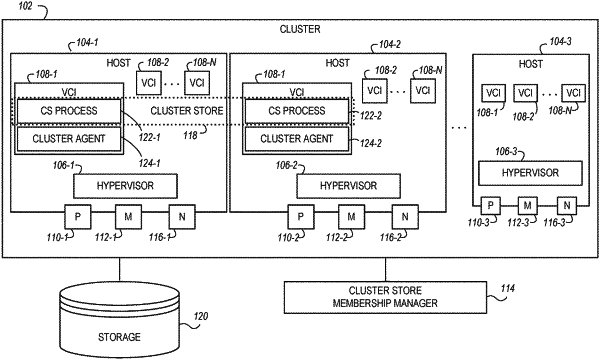
communicating a request for a health status to a cluster store provided by a cluster of hosts of a software-defined datacenter, wherein the cluster store includes a plurality of process instances undergoing a rolling upgrade;
receiving a health status indication in response to the request, the health status indication determined based on:
a determination of whether the cluster store is available such that a client of the cluster store can perform read and write operations on the cluster store, wherein determining whether the cluster store is available includes determining whether the cluster store comprises a quorum of process instances to achieve distributed consensus; and
a determination of whether the cluster store is operational;
wherein the health status indication comprises one of:
a first health status indication responsive to a determination that the cluster store is available and operational;
a second health status indication responsive to a determination that the cluster store is operational and not available; and
a third health status indication responsive to a determination that the cluster store is nonoperational; and
taking a remediation action in response to the health status indication exceeding a threshold.
|