| CPC G06F 9/30036 (2013.01) [G06F 11/1004 (2013.01)] | 15 Claims |
|
1. A processor comprising:
a register file comprising a plurality of vector registers; and
an execution core coupled to the register file, wherein the execution core is configured to execute a set of checksum instructions, wherein a first checksum instruction from the set of checksum instructions to specify a first vector operand, a second vector operand, and a result vector operand, wherein the first vector operand is in a first vector register of the plurality of vector registers, the second vector operand is in a second register of the plurality of vector registers, and the result vector operand is to be written to a third vector register of the plurality of vector registers, wherein to execute the first checksum instruction, the execution core is further configured to:
accumulate bytes from the first vector operand and the second vector operand into a first portion of the result vector operand and add the accumulated bytes from the first vector operand and the second vector operand to a previously generated value for a second portion of the result vector operand to generate the second portion written to the result vector operand, and wherein the execution core is further configured to:
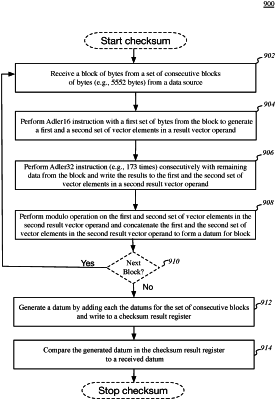
execute the first checksum instruction consecutively with a block from a set of consecutive blocks from a data source, wherein each block from the set of consecutive blocks has a defined number of bytes, and wherein the execution of the first checksum instruction with the block generates the result vector operand; and
execute a second checksum instruction, wherein the execution core is further configured to:
specify a third vector operand, a fourth vector operand, and a second result vector operand, wherein the third vector operand is in a fourth vector register of the plurality of vector registers, the fourth vector operand is in a fifth register, and the second result vector operand is to be written to a sixth vector register of the plurality of vector registers, wherein the execution core is configured to:
multiply a first portion of vector elements of a third vector operand by at least one vector element of a fourth vector operand to generate a vector written to the second result vector operand;
shift the second result vector operand by a defined value, wherein the defined value is computed to prevent overflow; and
multiply the second result vector operand by at least one vector element of the fourth vector operand to generate a subtraction value and subtracting the second result vector operand by the subtraction value.
|