| CPC G06F 3/167 (2013.01) [G06N 20/00 (2019.01); G06V 10/80 (2022.01); G06V 20/10 (2022.01); G06V 40/172 (2022.01); G10L 17/22 (2013.01)] | 20 Claims |
|
1. A method, by a user device, comprising:
receiving an input from a user;
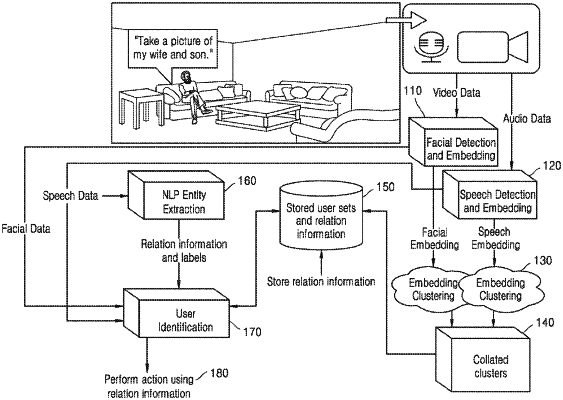
obtaining relation information of the user, audio information of the user obtained via a microphone of the user device, and video information of the user obtained via camera of the user device;
identifying the user based on the audio information and the video information of the user and a set of facial embeddings and speech embeddings that is correlated with the user, the set of facial embeddings and speech embeddings being generated using a facial embedding model, a speech embedding model, and a sound source localization model; and
performing an action based on the input and the relation information of the user,
wherein the sound source localization model is a model that is configured to determine the video information and the audio information that belongs to a same user.
|