| CPC G06F 3/0641 (2013.01) [G06F 3/067 (2013.01); G06F 3/0608 (2013.01); G06F 3/0659 (2013.01)] | 17 Claims |
|
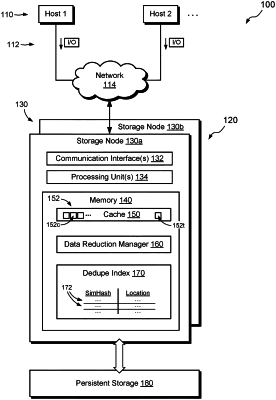
1. A method of performing data reduction, comprising:
receiving a sequence of datasets to be written in a data storage system, the sequence of datasets including a candidate dataset and an adjacent candidate dataset;
upon detecting a match between similarity hashes of the candidate dataset and a target dataset, performing a similarity assessment between the adjacent candidate dataset and an adjacent target dataset adjacent to the target dataset; and
in response to the similarity assessment determining that the adjacent candidate dataset and the adjacent target dataset are similar to at least a predetermined degree, performing a data reduction operation on the adjacent candidate dataset with reference to the adjacent target dataset,
wherein performing the similarity assessment includes:
accessing P hash values calculated from the adjacent candidate dataset and P hash values calculated from the adjacent target dataset;
selecting N of the P hash values, N<P and being less than one-tenth of P, of the adjacent candidate block based on a selection rule;
selecting N of the P hash values of the adjacent target block based on the same selection rule; and
determining that the adjacent candidate block is similar to the adjacent target block based at least in part on a number of matches between the N selected hash values of the adjacent candidate block and the N selected hash values of the adjacent target block.
|