| CPC G10L 15/26 (2013.01) [G10L 15/183 (2013.01)] | 21 Claims |
|
1. An apparatus comprising:
one or more processors; and
one or more memories storing thereon computer-readable instructions that, when executed by the one or more processors, cause the one or more processors to perform acts comprising:
initializing parameters of a machine translation model according to parameters of a language model;
training the machine translation model using training samples to obtain a trained machine translation model;
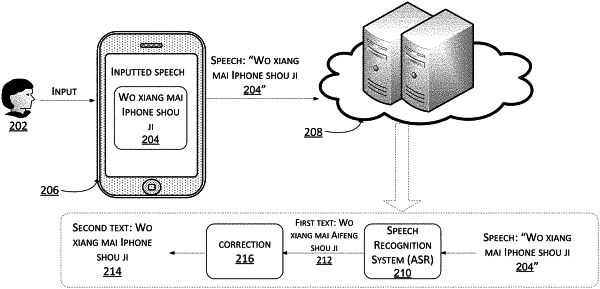
performing speech recognition on an inputted speech to obtain a first text;
correcting, by inputting the first text into the trained machine translation model, the first text according to a mapping relationship between words in different languages to obtain at least one second text;
obtaining respective first probability values predicted by the trained machine translation model corresponding to respective second texts of the at least one second text; and
determining an output text at least according to the respective first probability values corresponding to the respective second texts of the at least one second text, a respective first probability value representing a probability that the first text is corrected to a respective second text in the at least one second text, the determining the output text at least according to the respective first probability values corresponding to the respective second texts including:
inputting the at least one second text into the language model to determine respective second probability values corresponding to the respective second texts of the at least one second text using the language model, a respective second probability value representing a reasonableness of grammar and semantics of the respective second text;
determining the output text according to the respective first probability values and the respective second probability values corresponding to the respective second texts;
in response to determining that the first text is consistent with a particular second text having a largest summed probability value, outputting the first text, a respective summed probability value of the respective second text representing a weighted sum of the respective first probability value and the respective second probability value corresponding to the respective second text; and
in response to determining that the first text is inconsistent with the particular second text having the largest summed probability value, outputting the particular second text having the largest summed probability value.
|