| CPC G06V 10/25 (2022.01) [G06T 7/20 (2013.01); G06V 10/40 (2022.01); G06V 10/764 (2022.01); G06V 10/82 (2022.01); G06V 20/58 (2022.01); G06T 2207/10016 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/30196 (2013.01); G06T 2207/30261 (2013.01)] | 17 Claims |
|
1. A method for tracking a vulnerable road user (VRU) regardless of occlusion, the method comprising:
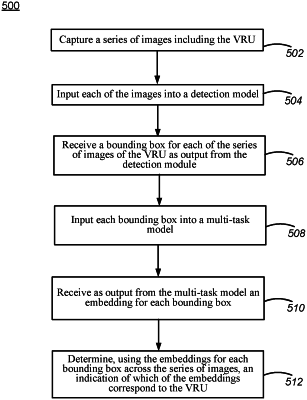
capturing a series of images comprising a plurality of human VRUs including the VRU, the VRU at least partially occluded in at least some images of the series of images;
inputting each of the images into a detection model;
receiving a bounding box for each of the series of images of the VRU as output from the detection model;
inputting each bounding box into a multi-task model;
receiving as output from the multi-task model an embedding for each bounding box, the embedding produced from a shared layer of the multi-task model, the multi-task model comprising the shared layer and a plurality of branches each trained to predict a different activity, wherein the shared layer is trained using backpropagation from the plurality of branches; and
determining, using the embeddings for each bounding box across the series of images, an indication of which of the embeddings correspond to the VRU as opposed to a different VRU of the plurality of human VRUs despite the partial occlusion of the VRU, wherein determining the indication of which of the embeddings correspond to the VRU comprises:
inputting each embedding into an unsupervised learning model; and
receiving as output, from the unsupervised learning model, an indication of a cluster of embeddings to which each embedding corresponds, each cluster corresponding to a different VRU of the plurality of human VRUs.
|