| CPC G06Q 50/184 (2013.01) [G06F 40/137 (2020.01); G06F 40/247 (2020.01); G06F 40/253 (2020.01); G06F 40/263 (2020.01); G06F 40/284 (2020.01)] | 20 Claims |
|
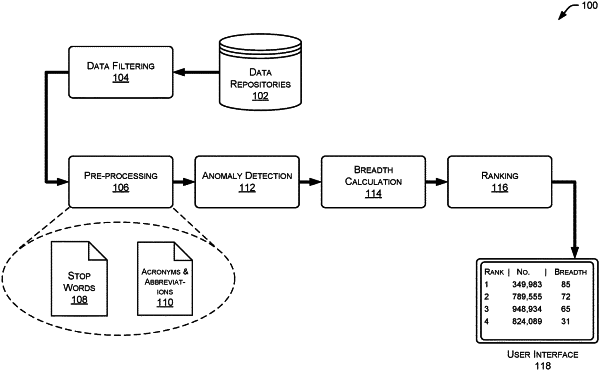
1. A computer-implemented method comprising:
receiving documents containing text written in a type of natural language, individual ones of the documents associated with a generated document identification number;
generating one or more document portions for the individual ones of the documents;
generating a word count for individual ones of the document portions;
identifying a referential word count;
generating a word count ratio for individual ones of the document portions based at least in part on the referential word count and the word count for individual ones of the document portions;
determining a word frequency for the individual ones of the words included in the document portions;
generating a commonness score for the individual ones of the document portions based at least in part on the word frequency for the individual ones of the words in the document portions;
identifying a document portion of the document portions having a commonness score representing a highest commonness score of the individual ones of the document portions;
generating a commonness score ratio for the individual ones of the document portions by dividing the commonness score representing the highest commonness score by the commonness score for the individual ones of the document portions;
generating an overall score for the individual ones of the document portions based at least in part on the word count ratio and the commonness score ratio for the individual ones of the document portions; and
generating a user interface including at least one overall score for one of the document portions in proximity to the generated document identification number associated with the one of the document portions.
|