| CPC G06N 20/00 (2019.01) [G06F 18/217 (2023.01); G06F 18/285 (2023.01); G06N 5/02 (2013.01); G06N 7/01 (2023.01); H04L 67/02 (2013.01)] | 15 Claims |
|
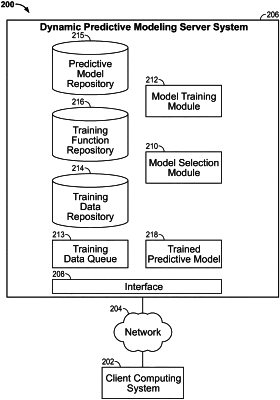
1. A computer-implemented method comprising:
receiving a plurality of first training data records of a first data type, wherein each first training data record includes an input data portion and an output data portion;
determining a first training data type that corresponds to the first training data records, comprising:
parsing each first training data record;
comparing the output data portions of the first training data records to a plurality of data formats;
based on the comparison, determining a match to a particular data format of the plurality of data formats and determining the first training data type based on the particular data format;
based on the determined first training data type, estimating, for each predictive model of a plurality of predictive models, an effectiveness the predictive model;
based on the estimation, selecting a proper subset of the predictive models;
training each predictive model of the proper subset of predictive models based on, at least, the first training data records;
scoring each predictive model in the proper subset of predictive models, each score for each model representing an estimation of the effectiveness of the respective trained predictive model for data records of the first data type; and
selecting, as a first selected predictive model for use with the first data type, a trained predictive model having a highest score from the proper subset of predictive models.
|