| CPC G06N 3/084 (2013.01) [G06N 3/048 (2023.01)] | 12 Claims |
|
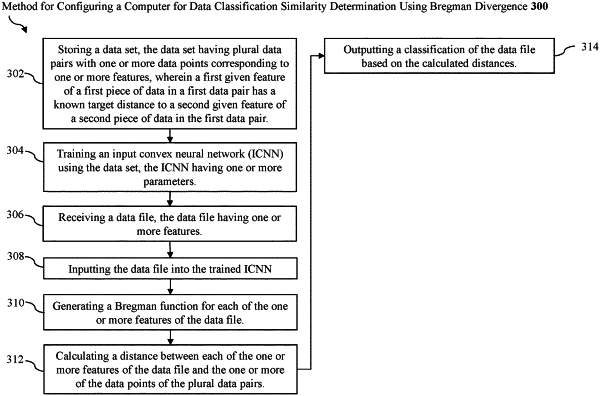
1. A method for configuring a computer for data similarity determination using Bregman divergence, the method comprising:
storing a data set, the data set having plural data pairs with one or more data points corresponding to one or more features, wherein a first given feature of a first piece of data in a first data pair has a known target distance to a second given feature of a second piece of data in the first data pair; and
training an input convex neural network (ICNN) using the data set, the ICNN having one or more parameters, wherein training the ICNN includes:
for each data pair within the data set:
extracting one or more features for each piece of data in the first data pair;
generating an empirical Bregman divergence for the data pair; and
computing one or more gradients between the one or more features within the first data pair based on the known target distance between the one or more features of the first data pair and the empirical Bregman divergence, the one or more gradients being computed using double backpropagation, automatic differentiation to compute the one or more gradients with respect to one or more data inputs, and a dot-product between the one or more gradients and another value;
generating a trained ICNN configured to output an arbitrary Bregman divergence function within a space of all possible Bregman divergences for a data pair based on the one or more gradients;
receiving a data file, the data file having one or more features;
inputting the data file into the trained ICNN;
generating a Bregman function for each of the one or more features of the data file, the one or more features including at least one of curvature and angularity;
calculating a distance between the one or more features of the data file and the one or more data points of the plural data pairs; and
outputting a classification of the data file based on the calculated distance.
|