| CPC G06F 40/30 (2020.01) [G06F 40/253 (2020.01); G06F 40/284 (2020.01); G06F 40/295 (2020.01); G06N 3/04 (2013.01); G06N 3/08 (2013.01); G16H 10/20 (2018.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
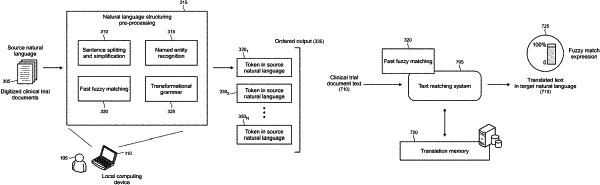
splitting sentences in a digitized text of a stored document into segments;
ordering words in the segmented sentences having reduced complexity relative to the sentences prior to splitting;
at least partially translating the segments to a target natural language by matching the ordered segments to segments in a database of documents previously translated from a source natural language, wherein content of the documents have similar subject matter as the new document;
producing a single representation of the sentences that share a common meaning by applying transformational grammar to the digitized text; and
outputting a representation of the stored document that includes a semantic meaning in the target natural language.
|
|
17. A computer-implemented method comprising:
splitting the digitized text in a new document into segments by identifying sentence boundaries using a gazetteer list of abbreviations to identify sentence marking stops;
identifying, using named entity recognition, the digitized text that is excluded from translation to a target natural language;
searching, using fuzzy matching, a translation history from the source natural language to the target natural language, for the segments between and existing translations;
identifying and tagging parts of speech in the digitized text;
grammatically transforming the digitized text to provide a single representation of sentences that have a common meaning;
over an application programming interface (API):
transmitting the segments to an external translation engine for translation;
receiving a translation of the segments in the target natural language from the external translation engine;
correcting the translation for subject matter specific acronyms and/or subject matter specific terminology; and
reconstructing the new document using the corrected translation in the target natural language.
|