| CPC G06F 16/3329 (2019.01) [G06F 16/3344 (2019.01); G06F 18/214 (2023.01); G06F 40/253 (2020.01); G06N 3/044 (2023.01); G06N 3/08 (2013.01); G06Q 50/18 (2013.01)] | 11 Claims |
|
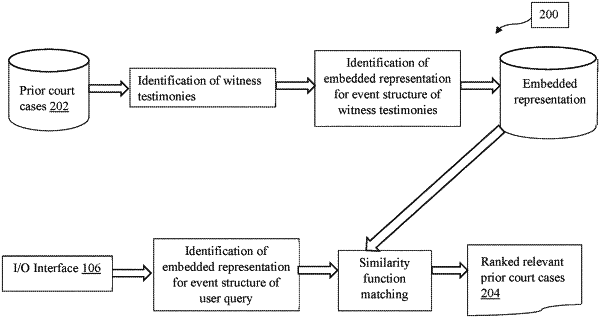
1. A processor implemented method for retrieving one or more prior court cases using witness testimonies, the method comprising:
receiving, via one or more hardware processors, a user query for retrieving one or more prior court cases, wherein the one or more prior court cases comprise a set of testimony sentences and a set of non-testimony sentences, wherein the user query and each testimony sentence of the set of testimony sentences comprise an event structure with a predicate and one or more arguments;
obtaining an embedded representation for the event structure of the user query, using a trained denoising auto-encoder executed via the one or more hardware processors, wherein the denoising auto-encoder is trained using one or more testimony sentences from the set of testimony sentences wherein the one or more testimony sentences are identified using a trained classifier and a set of linguistic rules, wherein the trained classifier is trained using a set of training data, wherein the set of training data comprises of
(i) the set of testimony sentences satisfying a set of predefined linguistic rules,
(ii) the set of non-testimony sentences satisfying a subset of the set of predefined linguistic rules and
(iii) a set of sentences which are neither identified as testimony nor non-testimony by the linguistic rules and
wherein the set of predefined linguistic rules satisfied by the set of testimony sentences are:
(i) presence of explicit or implicit witness mentions wherein the implicit mentions is any one of (a) pronouns (b) person-indicating common nouns (c) actual person names,
(ii) presence of at least one statement-indicating verb,
(iii) dependency subtree rooted at the at least one statement indicating verb should contain at least one of the following: a clausal complement or open clausal complement,
(iv) the statement verb should not have a child which negates itself, and
(v) the statement verb should have at least one witness mention within its subject or agent dependency subtree but should not have any legal role mention within its subject or agent dependency subtree;
estimating, via the one or more hardware processors, a similarity between the obtained embedded representation of the user query and an embedded representation of each of the one or more testimony sentences using a similarity function;
assigning a relevance score, via the one or more hardware processors, to the one or more prior court cases associated with the one or more testimony sentences in accordance with the estimated similarity; and
retrieving a predefined number of prior court cases out of the one or more prior court cases, wherein the predefined number is decided based on the assigned relevance score.
|