| CPC G06F 11/079 (2013.01) [G06F 11/0706 (2013.01); G06F 11/0751 (2013.01); G06F 11/0778 (2013.01); G06F 11/0787 (2013.01); G06F 11/2263 (2013.01); G06N 5/047 (2013.01)] | 15 Claims |
|
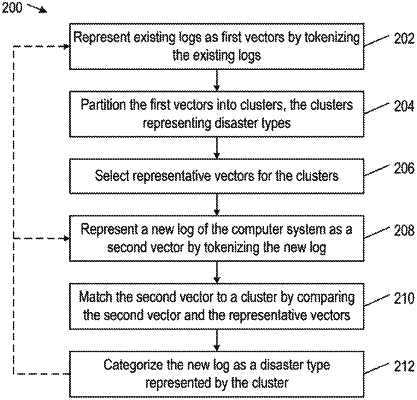
1. A method to predict a disaster for a computer system based on logs, the method comprising:
representing existing logs as first vectors by tokenizing the existing logs;
partitioning the first vectors into clusters, the clusters representing disaster types;
selecting representative vectors for the clusters;
representing a new log of the computer system as a second vector by tokenizing the new log;
matching the second vector to a cluster by comparing the second vector and the representative vectors; and
categorizing the new log as a disaster type represented by the cluster,
wherein matching the second vector to the cluster by comparing the second vector and the representative vectors comprises:
computing similarity scores between the second vector and the representative vectors;
determining if a highest similarity score is greater than a threshold, the highest similarity score being between the second vector and a representative vector of the cluster;
wherein when the highest similarity score is not greater than the threshold:
computing additional similarity scores between the second vector and first vectors in the cluster; and
when an additional similarity score is greater than the threshold, concluding the second vector matches the cluster.
|