| CPC G06F 1/3209 (2013.01) [G06F 1/3203 (2013.01); G06F 1/324 (2013.01); G06F 1/3212 (2013.01); G06F 1/3218 (2013.01); G06F 1/3231 (2013.01); G06F 3/01 (2013.01); G06F 11/0781 (2013.01); G06F 11/3062 (2013.01); H04W 52/0258 (2013.01); H04M 1/72448 (2021.01); Y02D 10/00 (2018.01); Y02D 30/70 (2020.08)] | 17 Claims |
|
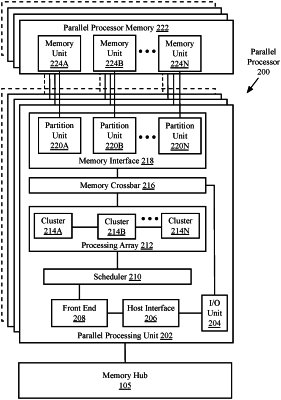
1. An apparatus comprising:
one or more processors including a graphics processing unit, the graphics processing unit including a graphics processing pipeline; and
a memory to store data, including graphics data processed by the graphics processing pipeline;
wherein the graphics processing unit is to:
conduct a training session with an application, the training session including a plurality of executions of the application utilizing the graphics processing pipeline, wherein the plurality of executions of the application includes executing the application under a plurality of different operating parameters, a plurality of different hardware configurations, or both;
collect performance data for the application during the plurality of executions of the application;
generate a performance profile for the application as processed in the graphics processing pipeline based on the collected performance data;
train a neural network to configure the graphics processing pipeline based on performance profile data from the performance profile for the application; and
utilize the trained neural network to configure the graphics processing pipeline to execute an instance of the application.
|