| CPC H04N 21/84 (2013.01) [G06N 20/00 (2019.01); H04N 19/126 (2014.11); H04N 21/43074 (2020.08); H04N 21/4662 (2013.01); H04N 21/4882 (2013.01); H04N 21/6587 (2013.01); H04N 21/8133 (2013.01); H04N 21/8456 (2013.01)] | 18 Claims |
|
1. A media rendering device, comprising:
a memory configured to store a trained machine learning (ML) model; and
circuitry configured to:
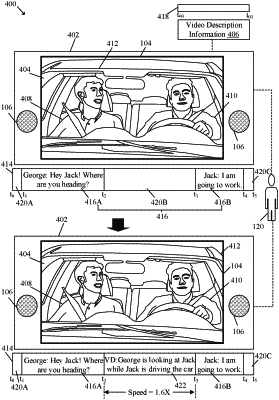
retrieve media content that comprises a set of filmed scenes and text information which includes video description information, speed information, and timing information, wherein
the video description information describes a filmed scene in the set of filmed scenes;
extract the timing information, to reproduce the video description information, from the text information of the filmed scene;
extract a first-time interval from the timing information, wherein
the first-time interval corresponds to a natural pause between consecutive audio portions of the filmed scene;
determine a set of second-time intervals of the filmed scene, wherein
each of the set of second-time intervals indicates a time interval for reproduction of an audio portion of the filmed scene in the set of filmed scenes;
determine a third-time interval which indicates a time duration required to reproduce an audio representation of the video description information of the filmed scene;
determine a multiplication factor based on a ratio of the determined third-time interval and the first-time interval;
determine a speed to reproduce the audio representation of the video description information based on the multiplication factor and an actual playback speed of the audio representation of the video description information; wherein the speed information indicates the speed for the reproduction of the audio representation of the video description information;
determine context information of the filmed scene based on an analysis of at least one characteristic of the filmed scene;
determine an audio characteristic to reproduce the audio representation of the video description information based on an application of the trained ML model on the determined context information of the filmed scene; and
control the reproduction of the audio representation of the video description information at the first-time interval indicated by the extracted timing information of the filmed scene, based on the speed information and the determined audio characteristic.
|