| CPC G10L 15/22 (2013.01) [G06F 3/165 (2013.01); G06F 3/167 (2013.01); G10L 15/32 (2013.01); G10L 15/30 (2013.01); G10L 2015/088 (2013.01); G10L 2015/223 (2013.01); H04R 27/00 (2013.01); H04R 2227/003 (2013.01); H04R 2227/005 (2013.01)] | 20 Claims |
|
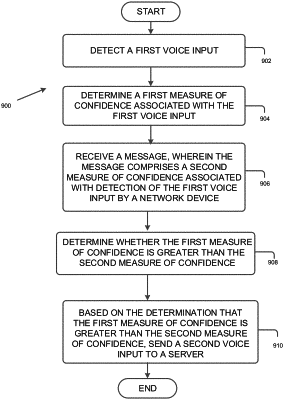
19. A method carried out by a computing device, the method comprising:
receiving, from a first NMD via a network interface of the computing device, a first arbitration message comprising (i) a first measure of confidence associated with a voice input as detected by the first NMD and (ii) the voice input as detected by the first NMD;
receiving, from a second NMD via the network interface, a second arbitration message comprising (i) a second measure of confidence associated with the voice input as detected by the second NMD and (ii) the voice input as detected by the second NMD;
determining that the second measure of confidence is greater than the first measure of confidence;
based on the determination that the second measure of confidence is greater than the first measure of confidence, performing voice recognition based on the voice input as detected by the second NMD, wherein the voice input as detected by the second NMD comprises a command to control playback of audio content by at least one of the first NMD or the second NMD; and
after performing voice recognition based on the voice input as detected by the second NMD, executing the command to control playback of audio content by at least one of the first NMD or the second NMD.
|