| CPC G10L 15/16 (2013.01) [G10L 15/083 (2013.01)] | 24 Claims |
|
1. A system comprising:
data processing hardware; and
memory hardware in communication with the data processing hardware and storing instructions that, when executed on the data processing hardware, cause the data processing hardware to perform operations, the operations comprising executing a recurrent neural network-transducer (RNN-T) model, the RNN-T model comprising:
an audio encoder configured to:
receive, as input, a sequence of acoustic frames; and
generate, at each of a plurality of time steps, a higher order feature representation for a corresponding acoustic frame in the sequence of acoustic frames;
a prediction network configured to, at each of the plurality of time steps subsequent to an initial time step:
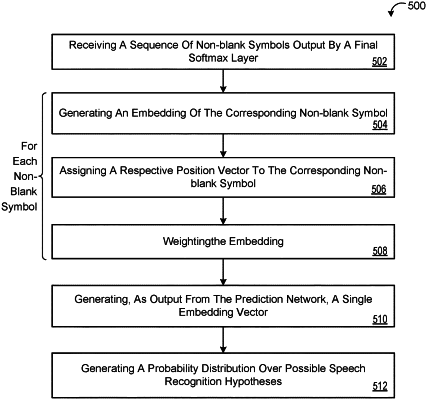
receive, as input, a sequence of non-blank symbols output by a final Softmax layer;
for each non-blank symbol in the sequence of non-blank symbols received as input at the corresponding time step:
generate, using a shared embedding matrix, an embedding of the corresponding non-blank symbol;
assign a respective position vector to the corresponding non-blank symbol; and
weight the embedding proportional to a similarity between the embedding and the respective position vector; and
generate, as output, a single embedding vector at the corresponding time step, the single embedding vector based on a weighted average of the weighted embeddings;
a joint network configured to, at each of the plurality of time steps subsequent to the initial time step:
receive, as input, the single embedding vector generated as output from the prediction network at the corresponding time step;
receive, as input, the higher order feature representation generated by the audio encoder at the corresponding time step; and
generate, as output, a probability distribution over possible speech recognition hypotheses at the corresponding time step; and
the final Softmax layer, the final Softmax layer configured to:
receive, as input, the probability distribution over possible speech recognition hypotheses generated as output from the joint network; and
determine, as output of the RNN-T model, a speech recognition result for the sequence of acoustic frames based on the probability distribution over possible speech recognition hypotheses.
|