| CPC G10L 13/027 (2013.01) [G06F 3/167 (2013.01); G10L 13/08 (2013.01); G10L 15/063 (2013.01); G10L 15/1807 (2013.01); G10L 15/22 (2013.01); G10L 15/26 (2013.01); G10L 25/63 (2013.01); G10L 2015/223 (2013.01)] | 16 Claims |
|
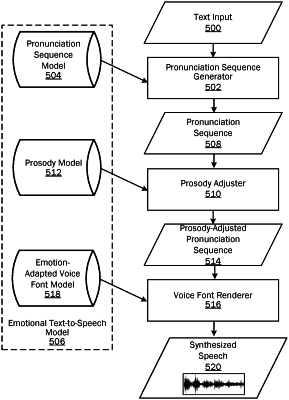
1. A system for adapting an emotional text-to-speech model, the system comprising:
at least one processor; and
memory, operatively connected to the at least one processor and storing instructions that, when executed by the at least processor, cause the at least one processor to:
receive training examples comprising speech input;
receive labelling data comprising emotion information associated with the speech input;
extract audio signal vectors from the training examples;
adapt a voice font model based on the audio signal vectors and the labelling data to generate an emotion-adapted voice font model;
generate first prosody annotations from the speech input;
generate second prosody annotations from the labelling data;
determine differences between the first prosody annotations and the second prosody annotations;
generate a prosody model based on the determined differences between the first prosody annotations and the second prosody annotations;
generate a prosody-adjusted pronunciation sequence for text input using the prosody model; and
render the text input to synthesized speech using the emotion-adapted voice font model and the prosody-adjusted pronunciation sequence.
|