| CPC G10L 13/00 (2013.01) [G06F 3/0482 (2013.01); G06F 3/167 (2013.01); G06F 16/358 (2019.01); G10L 13/047 (2013.01); G10L 13/08 (2013.01)] | 20 Claims |
|
1. A method implemented by at least one processing device, the method comprising:
receiving digital text;
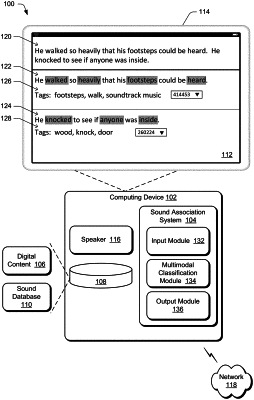
automatically identifying, using a text classification module of a multimodal classification module trained based on texts and sounds, an aurally active word in the digital text;
automatically identifying multiple context-based sounds corresponding to the aurally active word in the digital text using a sound classification module implemented in a deep neural network trained to identify one or more sound tags;
identifying multiple context-based sound identifiers based on the one or more sound tags, each context-based sound identifier being associated with one of the multiple context-based sounds;
displaying the digital text and the multiple context-based sound identifiers;
receiving user selection of a context-based sound of the multiple context-based sounds; and
presenting the digital text concurrently with the context-based sound including audibly outputting the context-based sound at a higher volume during a time that the aurally active word is determined to be read than during times that the aurally active word is not determined to be read, wherein the higher volume of the context-based sound is based on an attention weight generated by the text classification module for the aurally active word to which the context-based sound is anchored.
|