| CPC G06T 15/30 (2013.01) [G06T 7/10 (2017.01); G06T 15/06 (2013.01); G06T 15/08 (2013.01); G06T 15/40 (2013.01)] | 4 Claims |
|
1. A method for three dimensional (3D) un-occluded visualization of a focus, the method comprising:
generating a volumetric data set from a data source using at least one determined angle of view;
filtering out the focus which is at least one region of interest from a context which is at least one region surrounding the focus by performing semantic segmentation from the data source;
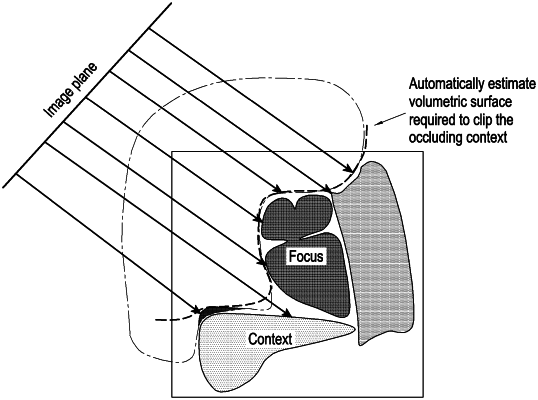
estimating a focus depth buffer for the focus by estimating intersection depths for a plurality of eye rays;
determining a set of boundary points around the focus;
initializing a 3-dimensional (3D) depth extrapolation model;
extrapolating a context depth buffer for the context using the estimated focus depth buffer, and at least one of a thin plate spline, or a radial basis function;
estimating a depth buffer from the estimated focus depth buffer and the extrapolated context depth buffer;
clipping the plurality of eye rays and corresponding light rays based on the estimated depth buffer;
generating a rendered data set using a volumetric clipping surface embedded in the depth buffer, and the clipped the plurality of eye rays;
generating a 3D image using the rendered data set; and
modulating at least one visual parameter of the generated 3D image to provide visualization effects,
wherein the focus is hidden by at least one region of the context,
wherein the rendered data set is generated, using the depth buffer to selectively render the focus and the context, and
wherein the volumetric clipping surface is estimated to maintain depth continuity on the set of boundary points of the focus and the context based on the depth buffer.
|