| CPC G06T 1/20 (2013.01) [G06F 9/3001 (2013.01); G06F 9/3017 (2013.01); G06F 9/3851 (2013.01); G06F 9/3887 (2013.01); G06F 9/3895 (2013.01); G06N 3/04 (2013.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/063 (2013.01); G06N 3/08 (2013.01); G06N 3/084 (2013.01)] | 20 Claims |
|
1. A compute apparatus to perform compute operations, the compute apparatus comprising:
a decode unit to decode a single instruction into a decoded instruction, the decoded instruction to cause the compute apparatus to perform a complex compute operation including multiple pipeline commands;
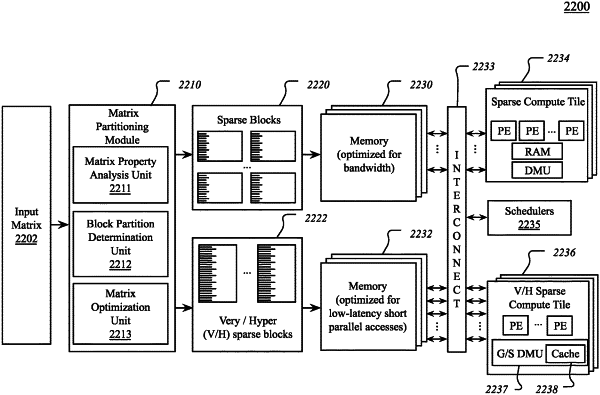
a micro-controller to execute firmware instructions, the firmware instructions to enable a parameter analyzer to determine a type of complex compute operation to perform for the single instruction; and
a scheduler controller to schedule the multiple pipeline commands for the complex compute operation to one or more of multiple types of compute units, wherein the multiple types of compute units include a first sparse compute unit configured for input at a first level of sparsity and a second sparse compute unit configured for input at a second level of sparsity that is higher than the first level of sparsity.
|