| CPC G06N 20/20 (2019.01) [G06F 9/5066 (2013.01); G06F 9/546 (2013.01)] | 23 Claims |
|
1. A computer-implemented method comprising:
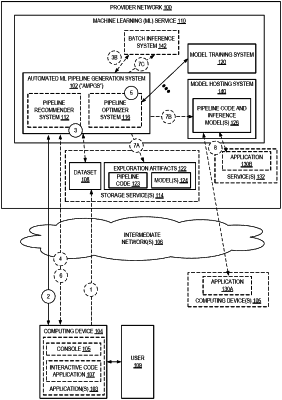
receiving, at an endpoint of a provider network, a request message originated by a computing device of a user to identify a machine learning (ML) pipeline based at least in part on a dataset, the request message identifying the dataset, an exploration budget, and an objective metric;
generating, based at least in part on the dataset, a plurality of ML pipeline plans, wherein each ML pipeline plan identifies at least one preprocessing stage and one ML model algorithm type;
transmitting a message to the computing device of the user that identifies the plurality of ML pipeline plans;
receiving a message originated by the computing device indicating a request to perform a ML pipeline exploration based on one or more of the plurality of ML pipeline plans;
initiating the ML pipeline exploration, the ML pipeline exploration including:
executing, at least partially in parallel, a plurality of preprocessing stages identified within the plurality of ML pipeline plans to yield a plurality of processed data sets, wherein each of the preprocessing stages utilizes at least some values of the dataset or values derived based on the dataset; and
executing a plurality of ML model training jobs, at least partially in parallel, each execution utilizing at least one of the plurality of processed data sets to train a ML model using one of the ML model algorithm types; and
transmitting data to the computing device of the user indicating a result of the ML pipeline exploration, the result indicating a value of the objective metric for each of the plurality of ML model training jobs.
|