| CPC G06N 3/08 (2013.01) [G06F 18/2148 (2023.01); G06F 40/205 (2020.01); G06F 40/40 (2020.01); G06F 40/30 (2020.01); G06N 3/088 (2013.01); G10L 15/16 (2013.01); G10L 15/18 (2013.01)] | 20 Claims |
|
8. A method for training a text-to-content recommendation machine-learning (ML) model, the method comprising:
training a first ML model using a first training data set;
providing as input to the trained first ML model a set of unlabeled unordered training data to generate a transfer data set;
training a pretrained text analysis model using a labeled training data set;
executing the pretrained text analysis model to generate an output; and
utilizing the transfer data set and the output to train the text-to-content recommendation ML model for recommending content based on text,
wherein:
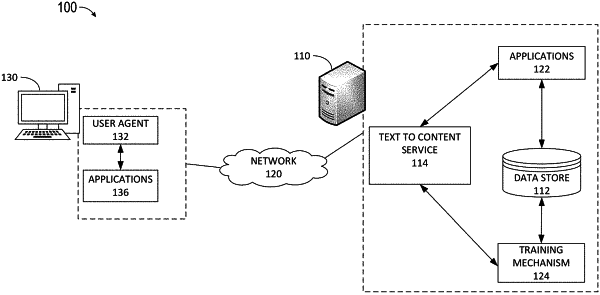
the text-to-content recommendation ML model is used by a text-to-content service provided by a server that receives a text portion as an input and provides the text portion to the text-to-content recommendation ML model and receives a plurality of recommendations for content that correspond with the text portion as an output of the text-to-content recommendation ML model, and
the server provides the plurality of recommendations for content to a backend unit that ranks the plurality of recommendations for presentation to a user.
|