| CPC G06N 3/08 (2013.01) [G06F 17/18 (2013.01); G06N 3/047 (2023.01)] | 20 Claims |
|
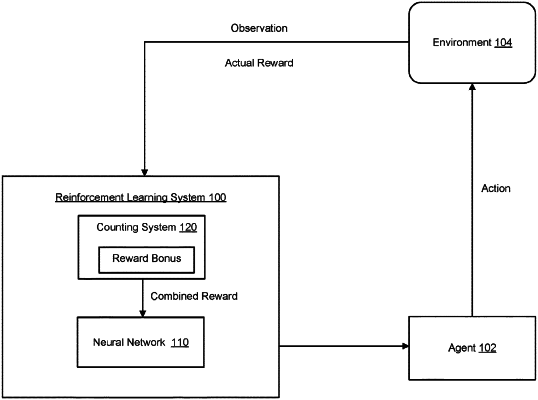
1. A computer-implemented method for training a neural network used to select actions to be performed by an agent interacting with an environment, the computer-implemented method comprising:
obtaining data identifying a first observation characterizing a first state of the environment;
selecting, using the neural network, an action to be performed by the agent in response to the first observation;
controlling the agent to perform the selected action;
receiving an actual reward resulting from the agent performing the action in response to the first observation;
determining a pseudo-count for the first observation using a sequential density model which represents a likelihood that the first observation occurs given a sequence of previous observations, wherein the pseudo-count depends upon a number of previous occurrences of the first observation during the training of the neural network;
determining an exploration reward bonus that incentivizes the agent to explore the environment from the pseudo-count for the first observation, wherein the exploration reward bonus is lower when the pseudo-count is higher and vice-versa;
generating a combined reward from the actual reward and the exploration reward bonus; and
training the neural network by adjusting current values of parameters of the neural network using the combined reward.
|