| CPC G06F 16/24542 (2019.01) [G06F 16/2228 (2019.01); G06F 16/24537 (2019.01); G06F 16/24549 (2019.01); G06N 20/00 (2019.01)] | 23 Claims |
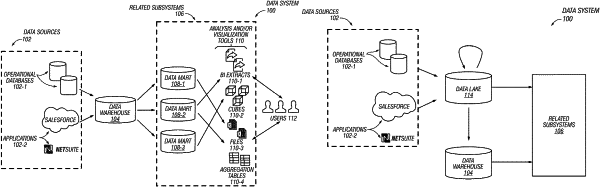
|
1. A computer-readable storage medium, excluding transitory signals and carrying instructions, which, when executed by at least one data processor of a data system, cause the data system to:
automatically determine relationships among a plurality of datasets based on a plurality of virtual datasets,
wherein the plurality of virtual datasets each include a query, a reference to a dataset of the plurality of datasets, and is created by a user of the data system;
generate an optimized data structure based on the relationships among the plurality of datasets,
wherein the optimized data structure is stored in a non-volatile memory of the data system;
receive a first query for a first result that satisfies the first query based on the plurality of datasets;
modify a first query plan for the first query to read the optimized data structure stored in the non-volatile memory in lieu of reading the plurality of datasets;
return the first result that satisfies the first query, wherein the first result is obtained based on the modified first query plan;
receive a second query for a second result that satisfies a second query different from the first query;
modify a second query plan for the second query to read the optimized data structure stored in the non-volatile memory; and
return the second result that satisfies the second query, wherein the second result is obtained based on the modified second query plan.
|