| CPC G06F 15/8046 (2013.01) [G06F 17/153 (2013.01); G06N 3/063 (2013.01)] | 8 Claims |
|
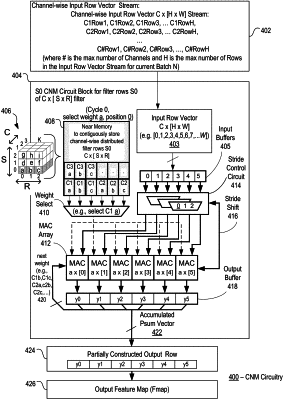
1. An integrated circuit comprising:
a memory to store one or more channels of a same filter row of a filter, each channel of the same filter row to be stored contiguously in the memory, row by row, in a channel-wise order;
an input buffer to receive one or more channels of input row vectors of input activations streamed to the input buffer, row by row, in the channel-wise order;
circuitry, including:
a multiplexer circuit to select a selected weight from a stored filter row, and
a multiplexer array to access the input activations from the input buffer based on a stride input and a weight position of the selected weight; and
at least one array of multiply and accumulate (MAC) units coupled to the circuitry, the at least one array of MAC units to compute, from the selected weight and the input activations, a partial sum for a convolution; and
wherein the circuitry enables access to the memory and the input buffer by the at least one array of MAC units to accelerate the convolution.
|