| CPC G06F 11/3409 (2013.01) [G06F 16/24568 (2019.01); G06F 16/313 (2019.01); G06F 16/35 (2019.01); G06F 16/9024 (2019.01); G06F 16/9535 (2019.01); G06Q 30/0201 (2013.01); G06Q 50/01 (2013.01); H04L 65/60 (2013.01)] | 20 Claims |
|
1. A method comprising:
at a computer system having real-time access to a data stream including a plurality of electronic communications, the computer system including at least one processor communicatively connected to a memory, executing instructions to cause the computer system to perform:
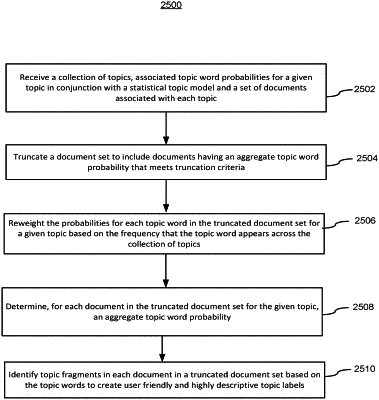
receiving a collection of topics, associated topic word probabilities in conjunction with a statistical topic model, and a set of documents associated with the collection of topics;
truncating the set of documents to form a truncated document set that includes documents having an aggregate topic word probability that meets truncation criteria;
determining, for each document in the truncated document set for a given topic, an aggregate topic word probability;
for one or more topic words in the truncated document set, identifying topic fragments including the one or more topic words and one or more non-stopwords, wherein identifying the topic fragments includes iterating from the one or more topic words and storing stopwords positioned relative to the one or more topic words until respective non-stopwords are identified; and
generating a topic label for the truncated document set including one or more of the identified topic fragments.
|