| CPC G10L 15/08 (2013.01) [G06F 16/636 (2019.01); G06F 21/32 (2013.01); G06V 40/10 (2022.01); G10L 15/07 (2013.01); G10L 15/22 (2013.01); G10L 17/00 (2013.01); G10L 17/06 (2013.01); G10L 15/26 (2013.01); G10L 2015/088 (2013.01)] | 19 Claims |
|
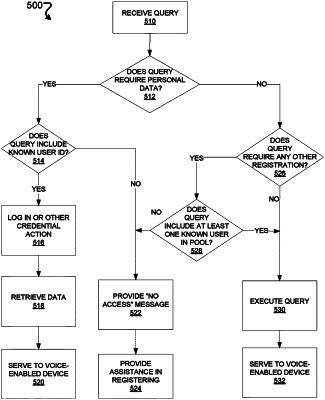
1. A method implemented by one or more processors comprising:
receiving an utterance from a speaker at a user device;
determining whether the speaker is a known user of the user device or not a known user of the user device that is shared by a plurality of known users;
determining whether the utterance corresponds to a personal request or non-personal request; and
in response to determining that the speaker is not a known user of the user device and in response to determining that the utterance corresponds to a non-personal request:
causing a response to the utterance to be provided for presentation to the speaker at the user device responsive to the utterance, or
causing an action to be performed by the user device responsive to the utterance.
|