| CPC G06V 40/23 (2022.01) [G06V 10/40 (2022.01); G06V 10/82 (2022.01)] | 10 Claims |
|
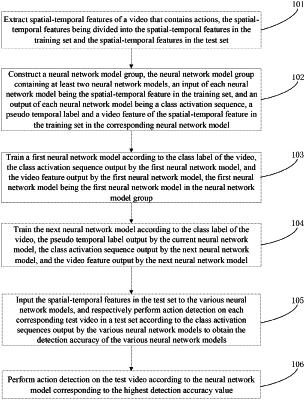
1. A weakly supervised video activity detection method based on iterative learning, comprising:
extracting spatial-temporal features of a video that contains actions, the spatial-temporal features being divided into the spatial-temporal features in the training set and the spatial-temporal features in the test set;
constructing a neural network model group, the neural network model group containing at least two neural network models, an input of each neural network model being the spatial-temporal feature in the training set, and an output of each neural network model being a class activation sequence, a pseudo temporal label and a video feature of the spatial-temporal feature in the training set in the corresponding neural network model;
training a first neural network model according to the class label of the video, the class activation sequence output by the first neural network model, and the video feature output by the first neural network model, the first neural network model being the first neural network model in the neural network model group;
training the next neural network model according to the class label of the video, the pseudo temporal label output by the current neural network model, the class activation sequence output by the next neural network model, and the video feature output by the next neural network model;
inputting the spatial-temporal features in the test set to the various neural network models, and respectively performing action detection on each corresponding test video in a test set according to the class activation sequences output by the various neural network models to obtain the detection accuracy of the various neural network models; and
performing action detection on the test video according to the neural network model corresponding to the highest detection accuracy value.
|