| CPC G06V 40/169 (2022.01) [G06V 10/22 (2022.01); G06V 10/87 (2022.01)] | 17 Claims |
|
1. A beauty prediction method based on multitasking and weak supervision, comprising the following steps:
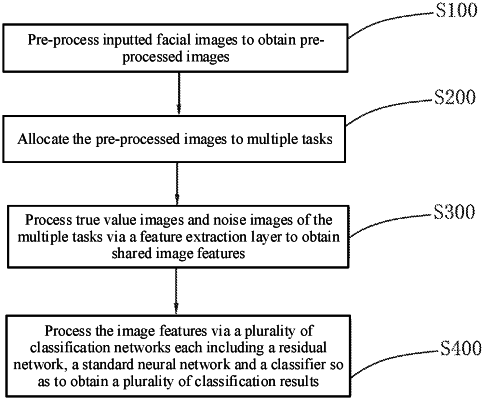
pre-processing inputted face images to obtain pre-processed images, wherein the pre-processed images comprise true value images marked with true value labels and noise images marked with noise labels;
allocating the pre-processed images to multiple tasks, wherein each task comprises a plurality of the true value images and a plurality of the noise images, and the multiple tasks comprise one main task specifically for facial beauty prediction and multiple auxiliary tasks related to the facial beauty prediction;
processing the true value images and noise images of the multiple tasks via a feature extraction layer to obtain shared image features; and
processing the image features via a plurality of classification networks each comprising a residual network, a standard neural network and a classifier to obtain a plurality of classification results, wherein each of the plurality of classification networks corresponds to a respective one of the multiple tasks,
wherein, in each of the classification networks, the residual network processes the image features, learns mapping from the image features to residual values of the true value labels and the noise labels and obtains a first predicted value; the standard neural network learns mapping from the image features to the true value labels and obtains a second predicted value; and each of the classification results is obtained by the classifier according to the first predicted value and the second predicted value.
|