| CPC G06T 17/05 (2013.01) [G06T 5/50 (2013.01); G06T 7/174 (2017.01); G06T 7/50 (2017.01); G06T 2207/10028 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/20221 (2013.01)] | 21 Claims |
|
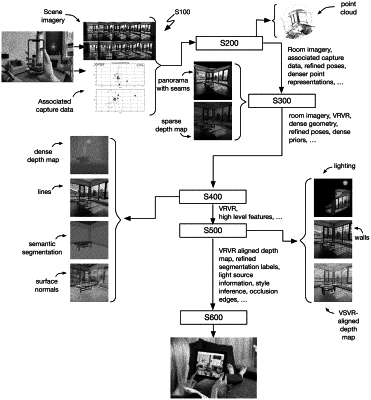
1. A method executed by one or more computing devices for generating a virtual representation of a physical scene, the method comprising:
receiving scene data corresponding to the physical scene;
processing the scene data to determine a plurality of scene components and a plurality of scene priors corresponding to the plurality of scene components, wherein the plurality of scene priors comprise a plurality of semantic segmentation masks and wherein processing the scene data comprises applying semantic segmentation to the scene data to generate a plurality of semantic segmentation masks, each semantic segmentation mask mapping a group of pixels in the scene data to a semantic label;
generating a plurality of dense geometric representations by inputting the plurality of scene priors into one or more neural networks trained to generate dense geometric representations, wherein each dense geometric representation corresponds to a scene component in the plurality of scene components;
generating a virtual model of the physical scene based at least in part on the plurality of dense geometric representations; and
generating a virtual representation of the physical scene based at least in part on the scene data, the virtual representation being aligned with the virtual model.
|