| CPC G06N 5/04 (2013.01) [G06F 16/215 (2019.01); G06F 16/24556 (2019.01); G06N 20/00 (2019.01); G06Q 10/10 (2013.01)] | 20 Claims |
|
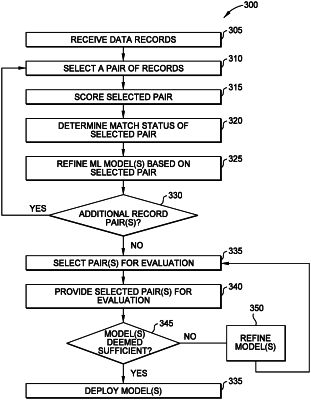
1. A method, comprising:
receiving a plurality of data records;
generating a first comparison vector by comparing a first and a second data records of the plurality of data records, wherein the first and second data records comprise values for a plurality of attributes related to an entity, wherein the first comparison vector indicates differences between the first and second data records in the plurality of attributes;
generating, by a probabilistic matching engine, a matching score based at least in part on the first comparison vector;
training a machine learning (ML) model based at least in part on the first comparison vector and the matching score, wherein the training the ML model comprises:
determining a match status of the first and second data records based at least in part on comparing the matching score with a threshold,
training the machine learning model using the first comparison vector as input and the match status as target output, and
upon determining that accuracy of the machine learning model satisfies one or more accuracy criteria, deploying the machine learning model;
evaluating, based on one or more generated comparison vectors, the plurality of data records using the trained machine learning model; and
linking at least two data records of the plurality of data records based on the evaluation.
|