| CPC G06N 3/08 (2013.01) [G06F 18/22 (2023.01); G06F 18/23 (2023.01); G06N 5/02 (2013.01); G06V 10/761 (2022.01); G06V 10/762 (2022.01); G06V 20/41 (2022.01); G06V 20/47 (2022.01); G06V 20/44 (2022.01)] | 20 Claims |
|
1. A computer-implemented method, comprising:
obtaining a plurality of videos, and for each video of the plurality of videos:
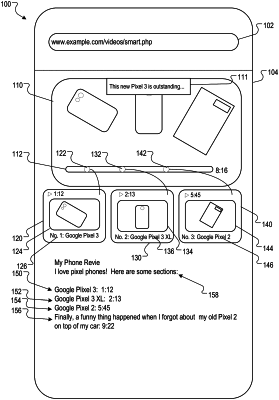
obtaining a set of anchors for the video, each anchor in the set of anchors for the video beginning at the playback time specified by a respective time index value of a time in the video, and each anchor in the set of anchors including anchor text;
identifying, from text generated from audio of the video, a set of entities specified in the text, wherein each entity in the set of entities is an entity specified in an entity corpus that defines a list of entities and is associated with a times stamp that indicates a time in the video at which the entity is mentioned;
determining, by a language model and from the text generated from the audio of the video, an importance value for each entity in the set of entities, each importance value indicating an importance of the entity for a context defined by the text generated from the audio of the video;
for a proper subset of the videos, receiving, for each video in the proper subset of videos, human rater data that describes, for each anchor for the video, the accuracy of the anchor text of the anchor in describing subject matter of the video beginning at the time index value specified by the respective time index value of the anchor; and
training, using the human rater data, the importance values, the text generated from the audio of the videos, the set of entities, an anchor model that predicts an entity label for an anchor for a video at a particular time in the video.
|