| CPC G06N 3/08 (2013.01) [G06F 17/16 (2013.01); G06F 18/22 (2023.01); G06F 18/23 (2023.01); G06V 10/764 (2022.01); G06V 10/774 (2022.01); G06V 10/7715 (2022.01); G06V 10/82 (2022.01)] | 18 Claims |
|
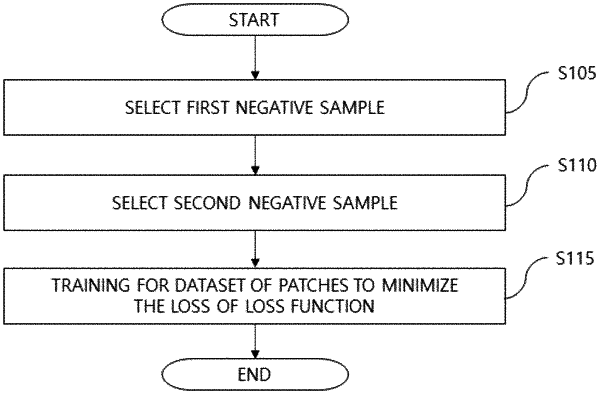
1. Method of training an image deep learning model comprising:
sampling a twin negative comprising a first negative sample and a second negative sample, the sampling includes:
selecting the first negative sample, the first negative sample having a highest, among a plurality of predefined classes, similarity to either of an anchor sample and a positive sample in which the anchor sample and the positive sample are a matching pair in a class of the plurality of predefined classes and different from a class of the first negative sample; and
selecting the second negative sample in which the second negative sample has a highest, among classes of the plurality of predefined classes that are different from the class of the matching pair and different from the class of the first negative sample, similarity to the first negative sample; and
training the image deep learning model, based on the anchor sample, the positive sample, and the first and second negative samples, to minimize a loss of a loss function in each class.
|