| CPC G06F 18/253 (2023.01) [G06F 16/532 (2019.01); G06F 16/538 (2019.01); G06F 16/5846 (2019.01); G06F 18/214 (2023.01); G06F 18/251 (2023.01); G06N 3/04 (2013.01)] | 20 Claims |
|
8. A system for performing an image search, the system comprising:
one or more non-transitory computer readable media;
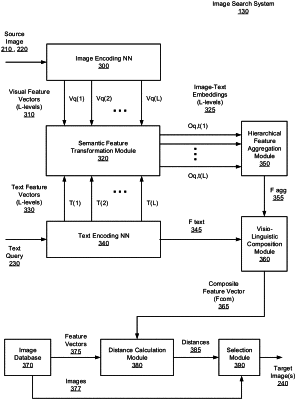
one or more processors configured to receive a source image and a text query defining a target image attribute, wherein the source image includes visual features and textual features;
a first neural network (NN) trained to decompose the source image into a first visual feature vector associated with a first level of granularity, and a second visual feature vector associated with a second level of granularity;
a second NN trained to decompose the text query into a first text feature vector associated with the first level of granularity, a second text feature vector associated with the second level of granularity, and a global text feature vector, wherein the global text feature vector spans multiple levels of granularity;
a semantic feature transformation module, encoded on the one or more non-transitory computer readable media, configured to generate a first image-text embedding based on the first visual feature vector and the first text feature vector, and a second image-text embedding based on the second visual feature vector and the second text feature vector, wherein the first and second image-text embeddings each encode information from the visual features and the textual features;
a visio-linguistic composition module, encoded on the one or more non-transitory computer readable media, configured to compose a visio-linguistic representation based on a hierarchical aggregation of the first image-text embedding with the second image-text embedding, wherein the visio-linguistic representation encodes a combination of visual and textual information at multiple levels of granularity; and
a selection module, encoded on the one or more non-transitory computer readable media, configured to identify a target image that includes the visio-linguistic representation and the global text feature vector, so that the target image relates to the target image attribute, the target image to be provided as a result of the image search.
|