| CPC G06F 16/9024 (2019.01) [G06F 16/9027 (2019.01)] | 20 Claims |
|
1. A method comprising:
during a loading of a graph that is distributed in a multi-node computing system into memory, determining a plurality of available IDs, each of which is unique, for a plurality of unidentified graph components of the graph;
wherein the graph comprises a plurality of existing graph components and is distributed in the multi-node computing system, wherein each vertex in the graph is in a node in the multi-node computing system and each edge in the graph connects a source vertex with a destination vertex in the graph;
wherein each of the plurality of unidentified graph components is a vertex or an edge, in the graph, that is not associated with a unique ID;
wherein determining the plurality of available IDs for the plurality of unidentified graph components comprises:
at each node in the multi-node computing system:
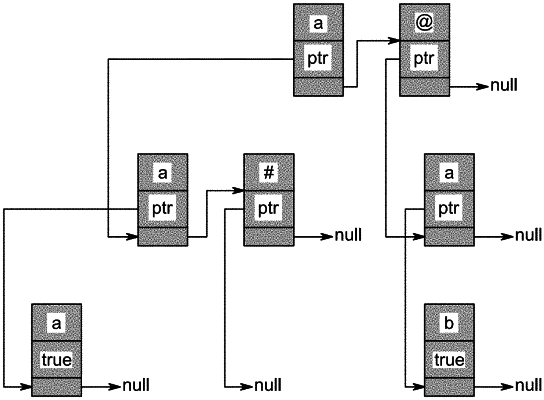
generating a local data structure comprising a plurality of arrays;
wherein each of the plurality of arrays comprises K slots, K being a whole number greater than one, wherein the K slots of a respective array representing a subdomain of identifiers associated with a domain of possible identifiers;
wherein the plurality of arrays includes a root array in a root layer associated with the domain, a plurality of parent arrays, and a plurality of child arrays, wherein each child array of the plurality of arrays is linked with a slot in a respective parent array;
wherein a property of each slot in each of the plurality of arrays indicates an availability of IDs, in the subdomain represented by a respective slot; and
wherein generating the local data structure comprises, for each of the plurality of existing graph components:
inserting an ID of a respective existing graph component into a corresponding slot in the local data structure; and
deleting all sublayers of the corresponding slot responsive to determining the corresponding slot is full;
generating a merged data structure using data from the local data structure and data from local data structures associated with other nodes in the multi-node computing system; and
traversing the merged data structure to identify the plurality of available IDs based on the property of each slot in the merged data structure.
|