| CPC G06F 16/3344 (2019.01) [G06F 16/22 (2019.01); G06F 16/322 (2019.01); G06F 16/33 (2019.01); G06F 16/334 (2019.01); G06F 40/211 (2020.01); G06F 40/284 (2020.01); G06F 40/30 (2020.01)] | 10 Claims |
|
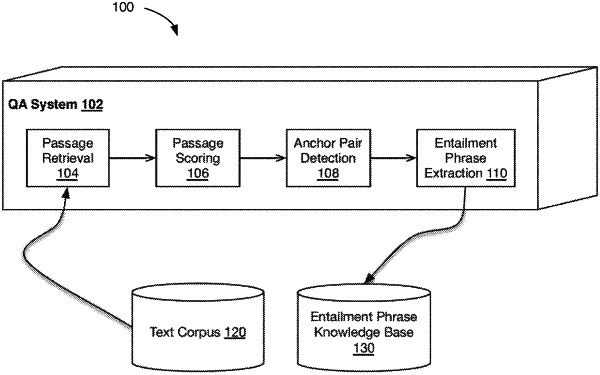
1. A method for generating a textual entailment pair by an electronic natural language processing system, comprising:
receiving first and second texts from an input source, wherein the input source is a QA pipeline;
querying a passage database using the first and second texts using an information retrieval engine in a natural language processing pipeline, wherein the first text is a question and the second text is a candidate answer;
retrieving a passage from the passage database in response to the query using the information retrieval engine in the natural language processing pipeline, wherein the passage is retrieved based on a highest ranking within a ranked list of passages, wherein the ranked list is based on an expected degree of relevance of textual data to a domain of the question;
identifying a plurality of anchor pairs in the first text and in the retrieved passage using one or more natural language processing class taggers built on top of one or more machine learning models, the one or more machine learning models being trained over a human annotated text corpora;
selecting a the plurality of anchor pairs in the first text and in the retrieved passage, using a plurality of term matchers, wherein each of the plurality of term matchers uses a corresponding algorithm to identify a match between a first anchor term in in the first text and a second anchor term in the passage retrieved,
the anchor pair comprising two anchor terms each corresponding to a term representing an entity linked across at least two passages or two questions;
generating an entailment pair based on the selected anchor pairs, the entailment pair comprising a pair of text fragments connecting the anchor terms in the at least two passages or two questions, wherein each text fragment within the pair of text fragments is a node,
wherein each node of the pair of text fragments connecting the anchor terms is a shortest path to an aligned focus subgraph, wherein the entailment pair is generated each time the pair of text fragments connecting the anchor terms is extracted;
assigning a score to the generated entailment pair, wherein the score assigned a first time the entailment pair is generated is an initial score;
retrieving at least one additional passage in response to at least one additional query;
performing term matching between terms in the question and terms in the at least one additional passage;
scoring the at least one additional passage based on the term matching and adjusting the ranking of the at least one additional passage within the ranked list of passages based on the at least one additional passage including the pair of text fragments connecting the anchor terms of the entailment pair;
generating the entailment pair at least one additional time based on the retrieving at least one additional passage in response to the at least one additional query, wherein the at least one additional passage includes the pair of text fragments connecting the anchor terms; wherein the score is adjusted each additional time the entailment pair is generated using a weighting multiplier based on a ranking of the at least one additional passage;
adjusting the score of the entailment pair in response to the at least one additional query based on one or more of the following factors: the ranking of the at least one additional passage, a frequency by which the entailment pair is extracted in response to the at least one additional query, or two or more different algorithms applied by DeepQA yielding the entailment pair in response to the at least one additional query:
storing the generated entailment pair in an entailment pair knowledgebase based on the score of the entailment pair exceeding a threshold value;
retrieving the generated entailment pair and at least one other entailment pair from the entailment pair knowledgebase, wherein both the generated entailment pair and the at least one other entailment pair exceed the threshold value; and
providing the generated entailment pair and the at least one other entailment pair to a process in the question-answering (QA) pipeline; and
adjusting the score of the generated entailment pair and the at least one other entailment pair based on the processing in the QA pipeline, wherein the score of the generated entailment pair and the at least one other entailment pair corresponds at least in part to a number of different questions whose processing results in retrieval.
|