| CPC G06F 16/285 (2019.01) [G06N 20/00 (2019.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
training, by a computing system, a machine learning model to generate a trained machine learning model configured to generate a distance score between a new data record and each of a plurality of representative data records, the training using training data based on history sourcing events data records on specified fields of the data records;
receiving, at a computing system, a request for a recommendation for a missing data field, the request comprising a new data record comprising a first data field with no data for which the recommendation is requested;
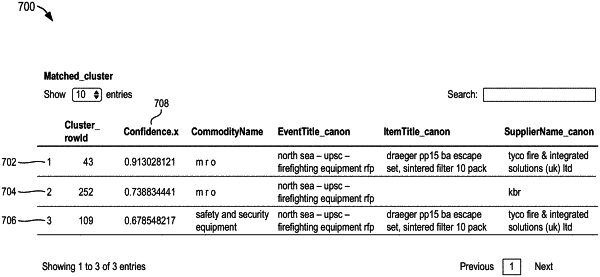
accessing, by the computing system, master data comprising a plurality of representative data records, each representative data record representing a cluster of similar data records, and each similar data record having a confidence score indicating a confidence level that the similar data record corresponds to the cluster;
comparing the new data record to each representative data record of the plurality of representative data records using the trained machine learning model to generate a distance score, for each representative data record, corresponding to a distance between the new data record and each representative data record;
selecting a set of representative data records having a generated distance score within a distance threshold of the new data record;
generating candidate values for the first data field with no data of the new data record by selecting, as a candidate value, a value of a second data field, in each record of the cluster of similar data records for each representative data record, that corresponds to the first data field;
generating a candidate score for each of the candidate values for the first data field with no data using the distance score for the representative data record representing the cluster of similar records to which the candidate value corresponds, and the confidence score for the similar data record to which the candidate value corresponds; and
providing a predefined number of recommendations for the first data field with no data based on the candidate scores for the candidate values.
|