| CPC G06F 16/282 (2019.01) [G06F 16/244 (2019.01); G06F 16/288 (2019.01); G06F 16/90324 (2019.01); G06F 18/2148 (2023.01); G06N 20/20 (2019.01)] | 18 Claims |
|
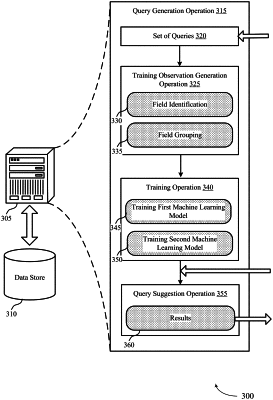
1. A computer-implemented method for building a machine learning model, comprising:
receiving a first plurality of queries, each query of the first plurality of queries comprising a plurality of fields in a tenant-specific dataset associated with the query;
parsing each query of the first plurality of queries to identify the plurality of fields included in the first plurality of queries;
identifying a first permutation and a second permutation of the plurality of fields;
grouping fields included in the first permutation in a first training data and fields included in the second permutation in a second training data;
storing a plurality of training data comprising the first training data and the second training data based on a subset of fields of the plurality of fields;
training a first machine learning model on the stored plurality of training data to determine grouping hierarchies comprising hierarchical relationships between the subset of fields of the plurality of fields based on a sequential order in which the subset of fields are grouped, wherein the sequential order filters fields based on a context, the sequential order being based on one or more data relationships among the fields of the subset of fields, the data relationship indicating that a first field is to follow a second field in accordance with the stored training data associated with the first field and the stored training data associated with the second field;
training a second machine learning model on the stored plurality of training data to determine aggregation predictions comprising predicated functions associated with one or more of the subset of fields of the plurality of fields; and
building a combined machine learning model based on the determined grouping hierarchies and the aggregation predictions.
|