| CPC G06F 16/245 (2019.01) [G06F 16/2255 (2019.01); G06F 16/248 (2019.01)] | 17 Claims |
|
1. A non-transitory computer readable medium comprising instructions that, when executed, cause one or more processors to:
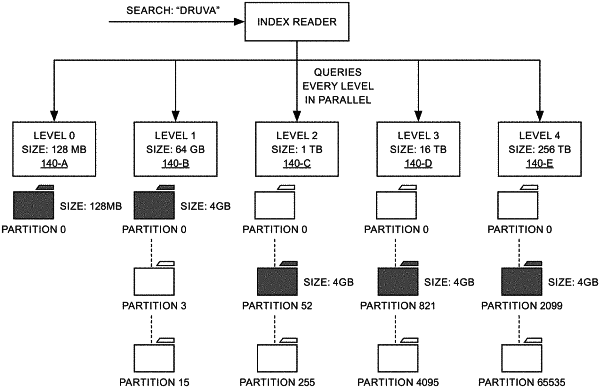
index the data set based on a plurality of index keys and one or more index value attributes;
create a plurality of directories, wherein each of the directories is at a different level and comprises a different number of hash partitions, wherein a data size limit of each directory of the plurality of directories is different, and wherein the number of hash partitions in the directory is based on the data size limit of the directory,
generate a hash table of values for each of the directories by hashing, based on a hash function, each of the index keys and the corresponding number of hash partitions in the corresponding directory,
write data from the indexed data set into the corresponding hash partition of one of the directories based on the respectively generated hash table,
identify a hash partition in each of the directories using the corresponding hash table,
query the identified hash partitions based on a search term to retrieve one or more relevant records, and
present the one or more retrieved records to a user.
|