| CPC G05D 1/0214 (2013.01) [G05D 1/0088 (2013.01); G05D 1/024 (2013.01); G05D 1/0221 (2013.01); G05D 1/0248 (2013.01); G05D 1/0274 (2013.01)] | 4 Claims |
|
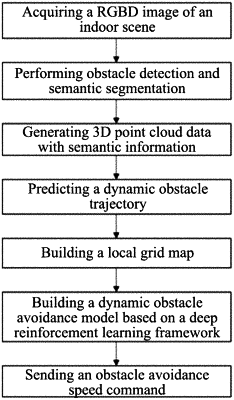
1. A dynamic obstacle avoidance method based on real-time local grid map construction, comprising:
(a) acquiring Red-Green-Blue-Depth (RGBD) image data of a real indoor scene by using a RGBD sensor;
(b) inputting the RGBD image data into a trained obstacle detection and semantic segmentation network to extract obstacles of different types and semantic segmentation results in the real indoor scene;
(c) combining the obstacles and semantic segmentation results with an internal parameter of the RGBD sensor and depth information acquired by the RGBD sensor; and generating three-dimension (3D) point cloud data with semantic information under the real indoor scene by using a spatial mapping relationship between two-dimension (2D) and 3D spaces;
(d) according to the 3D point cloud data generated in step (c), extracting state information of a dynamic obstacle followed by inputting to a trained dynamic obstacle trajectory prediction model, and predicting a trajectory of the dynamic obstacle in the real indoor scene;
wherein the step (d) comprises:
(d1) determining the state information of the dynamic obstacle; and designing a dynamic obstacle trajectory prediction model and a loss function of the dynamic obstacle trajectory prediction model;
wherein the step (d1) is performed through steps of:
(d11) for a set of dynamic obstacles
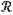 ={ri}i=1 . . . N currently detected, extracting a trajectory ={ri}i=1 . . . N currently detected, extracting a trajectory 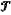 i={(x1, y1), (x2, y2), . . . , (xτ, yτ)} corresponding to an i-th dynamic obstacle in first τ frames of data; and obtaining state information Ωi i={(x1, y1), (x2, y2), . . . , (xτ, yτ)} corresponding to an i-th dynamic obstacle in first τ frames of data; and obtaining state information Ωi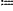 [ [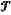 iΔ iΔ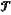 ic l]T of the i-th dynamic obstacle; ic l]T of the i-th dynamic obstacle;wherein N represents the number of dynamic obstacles in the set of dynamic obstacles; i represents an index of individual dynamic obstacles; (xτ, yτ) represents a spatial position of the i-th dynamic obstacle in a τ-th frame; Δ represents a derivative operator; := represents a define symbol; c represents a vector composed of dynamic densities of the i-th dynamic obstacle in individual frames of data, expressed as c
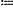 [c(x1, y1), . . . c(xτ,yτ)]T; c(x,y) represents a dynamic density of the i-th dynamic obstacle in a spatial position c(x,y); and l represents a size of the i-th dynamic obstacle; [c(x1, y1), . . . c(xτ,yτ)]T; c(x,y) represents a dynamic density of the i-th dynamic obstacle in a spatial position c(x,y); and l represents a size of the i-th dynamic obstacle;(d12) designing the dynamic obstacle trajectory prediction model, wherein the dynamic obstacle trajectory prediction model is formed by three one-dimensional (1D) convolutional layers and three fully-connected (FC) layers connected sequentially; the three 1D convolutional layers have 64, 32, and 32 channels, respectively; each of the three 1D convolutional layers has a kernel size of 3, and a stride of 1; the three FC layers have 256, 128, and 20 channels, respectively; and outputting spatial positions {(xτ+1,yτ+1), (xτ+2,yτ+2), . . . ,(xτ+10,yτ+10)} of the i-th dynamic obstacle in (τ+1)−(τ+10) frames after the last layer of the three FC layers; and
(d13) based on a real trajectory
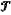 gti of the i-th dynamic obstacle, setting the loss function I of the dynamic obstacle trajectory prediction model, expressed as: gti of the i-th dynamic obstacle, setting the loss function I of the dynamic obstacle trajectory prediction model, expressed as: wherein w represents parameters of the dynamic obstacle trajectory prediction model; ϕ(wTΩi) represents a prediction trajectory of the i-th dynamic obstacle; and
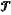 gti represents a real trajectory of the i-th dynamic obstacle; gti represents a real trajectory of the i-th dynamic obstacle;(d2) inputting the state information of the dynamic obstacle determined in step (d1) into the dynamic obstacle trajectory prediction model for training, until the loss function I of the dynamic obstacle trajectory prediction model converges, so as to obtain the trained dynamic obstacle trajectory prediction model; and
(d3) based on the 3D point cloud data, inputting the state information of the dynamic obstacle determined in step (d1) into the trained dynamic obstacle trajectory prediction model to predict the trajectory of the dynamic obstacle in the real indoor scene;
(e) according to the 3D point cloud data generated in step (c) and the trajectory of the dynamic obstacle predicted in step (d), building a real-time local grid map centered on a mobile robot with a radius of 3 m through steps of:
(e1) allowing the mobile robot to always face toward an east direction of the real-time local grid map; and setting a resolution of the real-time local grid map to 240×240, wherein each grid in the real-time local grid map represents a probability of the existence of an obstacle;
(e2) for a static obstacle in the real indoor scene, filling 1in a corresponding grid on the real-time local grid map;
(e3) for the dynamic obstacle, filling 1 in a current grid; filling a probability in individual grids covered by a predicted trajectory of the dynamic obstacle based on a distance between individual grids and a position of the dynamic obstacle, wherein the probability of individual grids covered by the predicted trajectory is one minus a ratio of a distance from a grid to a center of the dynamic obstacle to a length of the predicted trajectory;
(f) based on the real-time local grid map, building a dynamic obstacle avoidance model based on a deep reinforcement learning framework; and sending a speed instruction to the mobile robot in real time to avoid the obstacles of different types during a navigation process;
wherein the step (f) is performed through steps of:
(f1) determining a state input, an action space and a reward function of the dynamic obstacle avoidance model through steps of:
(f11) determining the state input of the dynamic obstacle avoidance model at moment t, wherein the state input comprises lidar data lt, the real-time local grid map, a position pt of a navigation target relative to the mobile robot, and an angular velocity wtgt and a linear velocity vtgt of the mobile robot; wherein the lidar data lt is obtained by a lidar sensor of the mobile robot, lt ϵR3×360, and R3×360 represents a matrix of 3×360;
(f12) determining the action space at the moment t, wherein the action space comprises moment (t+1) of the mobile robot, and an angular velocity wt+1 and a linear velocity vt+1 of the mobile robot, wherein wt+1 ϵ(−0.5,0.5), and vt+1 ϵ(0.0,1.0); and
(f13) building the reward function rt=rtp+rtc+rtn+rtw of the dynamic obstacle avoidance model at the moment t, wherein rtp represents a reward of the mobile robot when continuously approaching the navigation target; if the mobile robot reaches the navigation target, rtp=10.0, otherwise, rtp=∥xt−1−xp∥−∥xt−xp∥; xt−1 represents a position of the mobile robot in a global coordinate system at moment (t−1); xp represents a position of the navigation target in the global coordinate system; xt represents a position of the mobile robot in the global coordinate system at the moment t; rtc represents a penalty when the mobile robot encounters a collision, wherein if the collision occurs, rtc=−10.0, otherwise, rtc=0.0; rtn represents a penalty when the mobile robot approaches an obstacle, wherein if dth>dob, rtn=−0.1*∥dob−dth∥, otherwise, rtn=0.0; dob represents a current distance between the mobile robot and the obstacle; dth represents a distance threshold; rtw represents a penalty when a rotation speed of the mobile robot exceeds a threshold, wherein if |Δwt|>0.3, rtw=−0.1* ∥Δwt∥, otherwise, rtw=0.0; and Δwt represents a difference between the angular velocity wt+1 and the angular velocity wtgt, expressed as Δwt=wt+1−wtgt;
(f2) building and training the dynamic obstacle avoidance model until the reward function converges;
(f3) inputting the state input determined in step (f11) into a trained dynamic obstacle avoidance model, and outputting the speed instruction to the mobile robot to avoid the obstacles during the navigation process;
wherein the dynamic obstacle avoidance model based on the deep reinforcement learning framework comprises a first module for extracting features from the lidar data, a second module for extracting features from the real-time local grid map, a third module for extracting features from a relative position of the navigation target to the mobile robot, a fourth module for extracting features from a current speed of the mobile robot, a three-layer perceptron, and a FC layer with three branches;
an output end of the first module, an output end of the second module, an output end of the third module, and an output end of the fourth module are connected to an input end of the three-layer perceptron; and an output end of the three-layer perceptron is connected to the FC layer with three branches;
a first branch of the FC layer is configured to output an average velocity of the mobile robot in two dimensions, and the average velocity comprises an average angular velocity and an average linear velocity; a second branch of the FC layer is configured to output a velocity variance of the mobile robot in two dimensions, and the velocity variance comprises an angular velocity variance and a linear velocity variance; and a third branch of the FC layer is configured to output a dynamic obstacle avoidance evaluation value of one dimension;
the first module is composed of three 1D convolutional layers and one 256-dimensional FC layer connected sequentially; the three 1D convolutional layers have 32, 16 and 16 channels, respectively; each of the three 1D convolutional layers has a kernel size of 3 and a stride of 1;
the second module is composed of three 2D convolutional layers, one 512-dimensional FC layer, and one 256-dimensional FC layer connected sequentially; the three 2D convolutional layers have 64, 64, and 32 channels, respectively; the three 2D convolutional layers have a kernel size of 5×5, 5×5, and 3×3, respectively, and a stride of each of the three 2D convolutional layers is 2; and
the third module and the fourth module are each formed by one 32-dimensional FC layer.
|