| CPC G16H 70/00 (2018.01) [G16H 10/60 (2018.01)] | 20 Claims |
|
1. In a medical information navigation engine (“MINE”), a method for intent-based clustering of medical information, the method comprising:
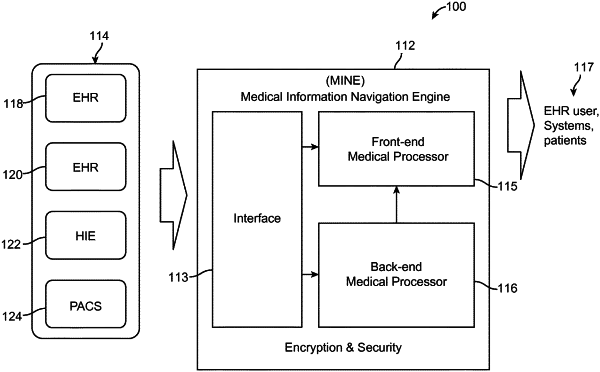
receiving medical information from electronic health records systems via a secure link in various electronic unstandardized source formats from a plurality of medical sources for a patient;
receiving on a series of database servers a first plurality of rules associating a plurality of medical terms to a plurality of medical concepts;
applying the first plurality of rules to the medical information to map a plurality of similarities in the medical information based upon identifying similar concepts to correlate information based upon those concepts;
receiving on the series of database servers a second plurality of rules that are user intent driven for clustering a characteristic of each of the medical concepts within an ontology, wherein the second plurality of rules determine what is considered inside of each cluster and learns whether information should belong within each cluster;
receiving a free text query from a user including one or more search terms related to one or more characteristics, wherein the free text query does not have restrictions of structure of the query;
filtering the medical information based upon the one or more characteristics and medical concepts associated with the one or more characteristics based upon the free text query;
determining user intent from the free text query;
receiving on the series of database servers a third plurality of rules for a time domain for each of the plurality of medical concepts, wherein the third plurality of rules learns how information in the cluster changes over time, wherein the third plurality of rules defines a plurality of time periods, each time period of the plurality of time periods associated with each of the plurality of medical concepts, for application of the second plurality of rules, and wherein the time periods are dynamically adjusted based upon the user intent in the free text query;
clustering in the series of database servers the medical information by the medical concepts with the one or more characteristics, the second plurality of rules, and the third plurality of rules to generate a time dependent data cluster, wherein the clustering includes a probability of match between the characteristic calculated as an abstract semantic distance along the ontology below a threshold;
providing a response to the free text query based upon the time dependent data cluster;
receiving user feedback based upon the time dependent data cluster;
determining one or more similarities based upon identifying similar concepts to correlate information based upon those concepts, wherein the one or more similarities are based upon the response and the user feedback, wherein the one or more similarities are determined through at least one of history, ontology, user-input, and type of user;
determining to update clustering rules and similarity mappings of at least one of the first plurality of rules, the second plurality of rules, or the third plurality of rules based upon the received user feedback and the determined one or more similarities, and wherein the first plurality of rules, the second plurality of rules, and the third plurality of rules progressively learns through at least one of history, ontology, user-input, and type of user; and
automatically updating the determined clustering rules and similarity mappings of at least one of the first plurality of rules, the second plurality of rules, or the third plurality of rules based upon the received feedback, so that the updated first plurality of rules, the second plurality of rules, or the third plurality of rules can be used in evaluating a subsequent query.
|