| CPC G10L 25/63 (2013.01) [G06F 40/30 (2020.01); G10L 17/02 (2013.01); G10L 17/16 (2013.01); G10L 21/0272 (2013.01); G10L 25/24 (2013.01)] | 20 Claims |
|
8. A device, comprising:
one or more memories; and
one or more processors, communicatively coupled to the one or more memories, configured to:
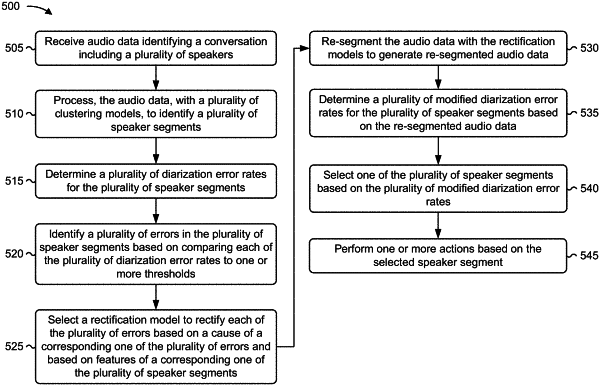
receive audio data identifying a conversation including a plurality of speakers;
process the audio data, with a plurality of clustering models, to identify a plurality of speaker segments,
wherein the plurality of clustering models includes a k-means clustering model, a spectral clustering model, and an agglomerative clustering model;
determine a plurality of diarization error rates for the plurality of speaker segments;
identify a plurality of errors in the plurality of speaker segments based on comparing each of the plurality of diarization error rates to a threshold;
select a rectification model to rectify each of the plurality of errors based on a cause of a corresponding one of the plurality of errors and based on features of a corresponding one of the plurality of speaker segments;
re-segment the audio data with the rectification model to generate re-segmented audio data;
determine a plurality of modified diarization error rates for the plurality of speaker segments based on the re-segmented audio data;
select one of the plurality of speaker segments based on the plurality of modified diarization error rates;
calculate an empathy score based on the one of the plurality of speaker segments and based on an emotion score, an intent score, and a sentiment score determined based on the re-segmented audio data;
retrain the rectification model based on calculating the empathy score and utilizing the empathy score as additional training data; and
perform one or more actions based on the empathy score.
|