| CPC G10L 15/22 (2013.01) [G10L 15/08 (2013.01); G10L 2015/088 (2013.01); G10L 2015/223 (2013.01)] | 10 Claims |
|
1. A system configured to recognize and execute spoken commands using speech recognition, the system comprising:
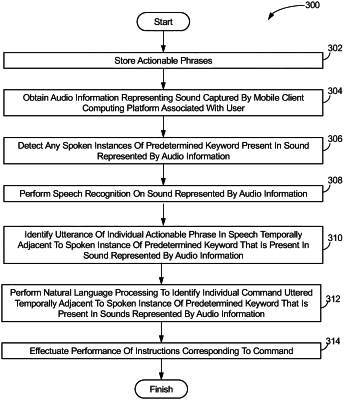
electronic storage media configured to store actionable phrases, individual actionable phrases correlating to individual commands, wherein the commands are used during documentation;
one or more processors configured by machine-readable instructions to:
obtain audio information representing sound captured by a mobile client computing platform associated with a user;
detect any spoken instances of a predetermined keyword present in the sound represented by the audio information;
perform speech recognition on the sound represented by the audio information;
responsive to detection of a spoken instance of the predetermined keyword present in the sound represented by the audio information, identify one or more utterances of actionable phrases in speech temporally adjacent to the spoken instance of the predetermined keyword that is present in the sound represented by the audio information;
responsive to detection of the spoken instance of the predetermined keyword present in the sound represented by the audio information and responsive to not identifying the one or more utterances of the actionable phrases in speech temporally adjacent to the spoken instance of the predetermined keyword that is present in the sound represented by the audio information, perform natural language processing to identify individual commands uttered temporally adjacent to the spoken instance of the predetermined keyword that is present in the sounds represented by the audio information; and
effectuate performance of instructions corresponding to the individual commands.
|