| CPC G06V 20/20 (2022.01) [B25J 9/1679 (2013.01); B25J 9/1697 (2013.01); G06T 17/00 (2013.01); G06V 20/41 (2022.01)] | 20 Claims |
|
1. A method, comprising:
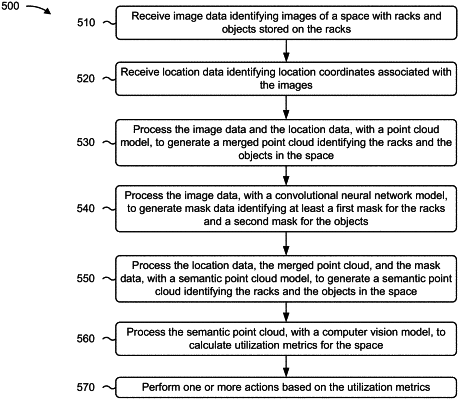
receiving, by a device, image data identifying images of a space with racks and objects stored on the racks;
receiving, by the device, location data identifying location coordinates associated with the images;
processing, by the device, the image data and the location data, with a point cloud model, to generate a merged point cloud identifying the racks and the objects in the space;
processing, by the device, the image data, with a convolutional neural network model, to generate mask data identifying at least a first mask for the racks and a second mask for the objects,
wherein processing the image data comprises:
identifying first portions of the image data that correspond to the racks,
grouping the first portions of the image data into a first group of data,
correlating the first mask with the first group of data,
identifying second portions of the image data that correspond to the objects,
grouping the second portions of the image data into a second group of data,
correlating the second mask with the second group of data,
identifying third portions of the image data that correspond to empty portions of the space,
grouping the third portions of the image data into a third group of data, and
correlating a third mask with the third group of data;
processing, by the device, the location data, the merged point cloud, and the mask data, with a semantic point cloud model, to generate a semantic point cloud identifying the racks and the objects in the space;
processing, by the device, the semantic point cloud, with a computer vision model, to calculate utilization metrics for the space; and
performing, by the device, one or more actions based on the utilization metrics.
|