| CPC G06V 10/235 (2022.01) [G06F 18/213 (2023.01); G06F 18/2413 (2023.01); G06F 18/40 (2023.01); G06T 7/12 (2017.01); G06T 11/203 (2013.01); G06T 2200/24 (2013.01); G06T 2207/30242 (2013.01)] | 18 Claims |
|
1. A system comprising:
at least one processor;
first memory, the first memory containing instructions to control any number of the at least one processor to:
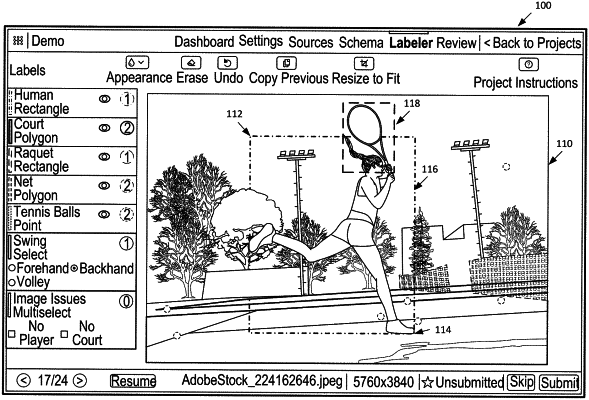
provide a first user interface displaying a first image taken by a first image capture device, the first image capture device including a first field of view, the first image including a depiction of a first object, the first object being of a particular type, the first image including a first bounding shape placed by a first user around the depiction of the first object using a shape tool provided by the first user interface;
extract a first portion of the first image, the first portion including only contents of the first image that are contained within the first bounding shape including the depiction of the first object;
retrieve first high-level features and first low-level features from the first portion, the first high-level features including low spatial information content and high semantic content of the first portion, the first low-level features including high spatial information content and low semantic content of the first portion;
apply first Atrous Spatial Pyramid Pooling (ASPP) to the first high-level features of the first portion to aggregate the first high-level features as first aggregate features, the applying the first ASPP including applying any number of convolutional layers in parallel and at different rates from each other to the first high-level features and concatenating results to create the first aggregate features;
up-sample the first aggregate features;
apply a convolution to the first low-level features;
concatenate the first aggregate features after upsampling with the first low-level features after convolution to form first combined features;
segment the first combined features to generate a first polygonal shape outline along first outer boundaries of the first object in the first portion, segmenting comprising batch normalization and application of a rectified linear activation function on the first combined features; and
display the first image in the first user interface and the first polygonal shape outline of the first object in the first user interface, the first image not including the first bounding shape placed by the first user; and
a second memory, the second memory containing instructions to control the any number of the at least one processor to:
receive a second image from a second image capture device, the second image capture device being positioned over a second path, the second image containing a depiction of a second object, the second object being of the particular type;
generate feature maps from the second image by applying at least a first convolutional neural network;
slide a first window across the feature maps to obtain a plurality of anchor shapes using a region proposal network;
determine if each anchor shape of the plurality of anchor shapes contains an object to generate a plurality of regions of interest, each of the plurality of regions of interest being a non-rectangular, polygonal shape;
extract feature maps from each region of interest;
classify objects in each region of interest using a pretrained convolutional neural network, trained in part using the first polygonal shape outline of the first object;
in parallel with classification, predict segmentation masks on at least a subset of the plurality of regions of interest in a pixel-to-pixel manner;
identify individual objects of the second image based on classifications and the segmentation masks;
count individual objects based on the identification; and
provide the count to a third digital device for display.
|