| CPC G06N 3/063 (2013.01) [G06N 3/0454 (2013.01); G06N 3/088 (2013.01)] | 25 Claims |
|
1. An apparatus comprising:
a processor comprising:
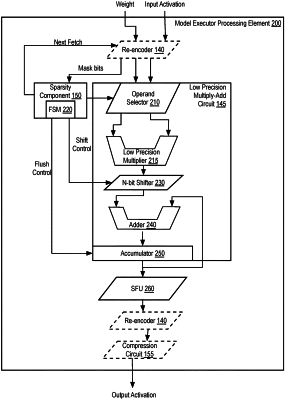
a re-encoder to re-encode a first input number of signed input numbers represented in a first precision format as part of a machine learning model, the first input number re-encoded into two signed input numbers of a second precision format, wherein the first precision format is a higher precision format than the second precision format;
a multiply-add circuit to perform operations in the first precision format using the two signed input numbers of the second precision format; and
a sparsity hardware circuit to reduce computing on zero values at the multiply-add circuit, wherein the sparsity hardware circuit comprises a finite state machine (FSM) to determine whether any of the two signed input numbers corresponding to most significant bits (MSBs) comprise zero values and to cause the multiply-add circuit to skip the operations on numbers comprising zero values;
wherein the processor to execute the machine learning model using the re-encoder, the multiply-add circuit, and the sparsity hardware circuit.
|