| CPC G06F 40/58 (2020.01) [G06F 40/44 (2020.01); G06F 40/47 (2020.01)] | 16 Claims |
|
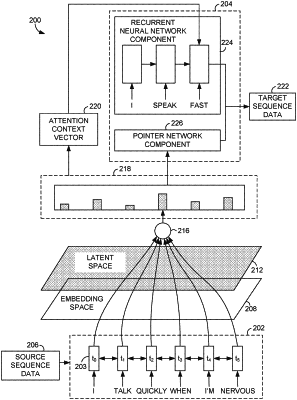
1. One or more computer-readable media having computer instructions stored thereon for execution by one or more processors, wherein execution of the computer instructions by the one or more processors provides a method for stylistic expression transfer, the media comprising:
obtaining, by an encoder component, source sequence data including one or more words;
encoding, by the encoder component, the source sequence data as one or more time steps;
applying an overall loss function at each of the one or more time steps to train an encoder-decoder model, wherein the overall loss function comprises a first weight applied to a cross entropy function, a second weight applied to a content function, and a third weight applied to a style transfer function;
selecting, by a decoder component, at least one word of the one or more words for the one or more time steps, wherein the one word is selected based on a content value and a style value of the one word; and
generating, by the decoder component, target sequence data that includes the at least one word that is selected, wherein the target sequence data is different from the source sequence data.
|