| CPC B25J 9/161 (2013.01) [B25J 9/163 (2013.01); B25J 9/1661 (2013.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
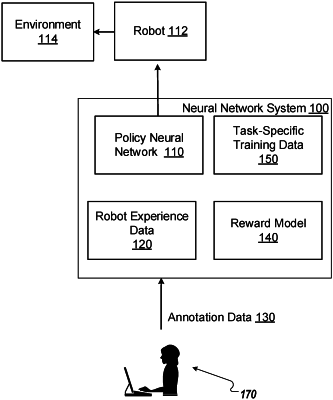
maintaining robot experience data characterizing robot interactions with an environment, the robot experience data comprising a plurality of experiences that each comprise an observation and an action performed by a respective robot in response to the observation;
obtaining annotation data that assigns, to each experience in a first subset of the experiences in the robot experience data, a respective task-specific reward for a particular task, wherein the first subset of experiences comprises experiences from a plurality of different task episodes of the particular task;
training, on the annotation data, a reward model that receives as input an input observation and generates as output a reward prediction that is a prediction of a task-specific reward for the particular task that should be assigned to the input observation, wherein training the reward model comprises training the reward model to optimize a loss function that includes a term that measures, for a given pair of experiences from a same task episode of the plurality of different task episodes, (i) a difference in a respective reward prediction generated by the reward model for a first observation in a first experience in the given pair and a respective reward prediction generated by the reward model for a second observation in a second experience in the given pair and (ii) a difference in a respective task-specific reward for the first experience in the given pair and a respective task-specific reward for the second experience in the given pair;
generating task-specific training data for the particular task that associates each of a plurality of experiences with a task-specific reward for the particular task, comprising, for each experience in a second subset of the experiences in the robot experience data:
processing the observation in the experience using the trained reward model to generate a reward prediction, and
associating the reward prediction with the experience; and
training a policy neural network on the task-specific training data for the particular task, wherein the policy neural network is configured to receive a network input comprising an observation and to generate a policy output that defines a control policy for a robot performing the particular task.
|