| CPC G10L 21/0308 (2013.01) [G06F 3/0481 (2013.01); G06F 3/167 (2013.01); G10L 17/06 (2013.01); G10L 17/24 (2013.01); G10L 21/028 (2013.01)] | 20 Claims |
|
1. A method comprising:
displaying, by way of a user interface of a computing device, a visual prompt for input of identity data;
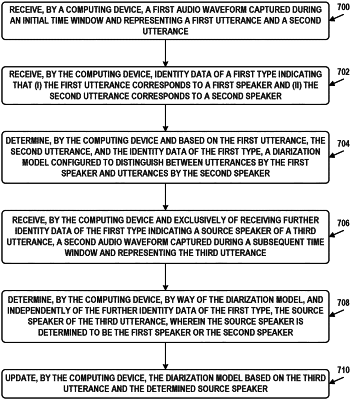
receiving, by the computing device, a first audio waveform captured during an initial time window and representing a first plurality of utterances by a first speaker and a second plurality of utterances by a second speaker;
receiving, by the computing device, the identity data of a first type indicating that (i) a first utterance of the first plurality of utterances corresponds to the first speaker and (ii) a second utterance of the second plurality of utterances corresponds to the second speaker;
determining, by the computing device and based on the first utterance, the second utterance, and the identity data of the first type, a diarization model configured to distinguish between utterances by the first speaker and utterances by the second speaker;
determining an accuracy of the diarization model in distinguishing between the first plurality of utterances and the second plurality of utterances;
determining that the accuracy exceeds a threshold accuracy;
based on determining that the accuracy exceeds the threshold accuracy, modifying the user interface to remove therefrom the visual prompt;
receiving, by the computing device and exclusively of receiving further identity data of the first type indicating a source speaker of a third utterance, a second audio waveform captured during a subsequent time window and representing the third utterance; and
determining, by the computing device, by way of the diarization model, and independently of the further identity data of the first type, the source speaker of the third utterance, wherein the source speaker is determined to be the first speaker or the second speaker.
|