| CPC G06N 20/20 (2019.01) [G06F 16/90332 (2019.01); G06F 17/18 (2013.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06N 20/00 (2019.01); G06N 20/10 (2019.01); G16H 10/20 (2018.01)] | 20 Claims |
|
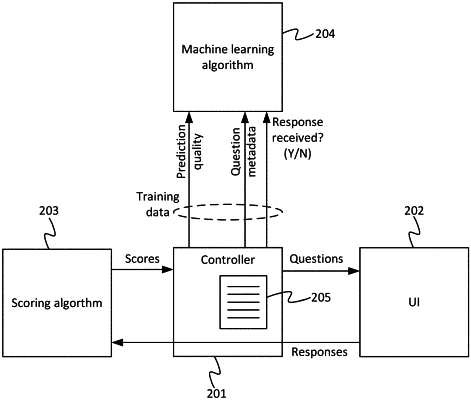
1. Computing apparatus comprising a processor and storage storing code arranged to run on the processor, wherein the code is configured so as when run to perform operations of:
outputting questions to a user via a user device, and receiving back responses to some of the questions from the user via the user device;
over time, controlling the outputting of the questions so as to output the questions with a different value associated with each item of a plurality of items of metadata, wherein the plurality of items of metadata comprise at least one of a time or a location at which a question was output to the user via the user device;
determining a probability distribution of an unanswered question of the questions; and
training a machine learning algorithm to learn a value of each of the items of metadata which optimizes a reward function based on the determined probability distribution, and based thereon selecting at least one of a time or location at which to output a subsequent question, wherein the reward function comprises a distance between the probability distribution of the unanswered question and a probability distribution based on an answered question of the questions.
|